Conclusion
As synthetic biology continues to evolve, with its goal of optimizing, engineering, and creating new biological systems, there is an increasing need to scale up experimental processes to match the growing complexity and ambition of the field. Synthetic biology encompasses a broad range of activities, from the design of novel genetic circuits and engineered microorganisms to the construction of entirely new metabolic pathways or synthetic life forms. These activities are inherently interdisciplinary, drawing on principles from genetics, molecular biology, systems biology, and engineering. However, as the scope of synthetic biology projects expands, the experimental methods and processes that underlie these innovations must also be scaled to accommodate the increased demand for high-throughput experimentation, more complex systems, and larger datasets.
Scaling up experimental processes in synthetic biology involves addressing several key challenges. First, the increased complexity of engineered biological systems often requires handling a larger number of variables, interacting components, and feedback loops, which necessitates more sophisticated experimental designs. For example, designing and testing large genetic libraries of engineered microbes or optimizing multi-step biosynthetic pathways can involve hundreds or thousands of individual experiments. These types of experiments are often resource-intensive and can take substantial amounts of time when done manually.
Second, the need for high-throughput capabilities is central to the scalability of synthetic biology experiments. Traditional experimental setups, which may involve manual cloning, PCR, protein expression, or phenotypic analysis, become increasingly impractical when scaling to large numbers of variants or conditions. High-throughput technologies, such as automated liquid handling systems, robotic platforms, and advanced imaging or sequencing technologies, can dramatically increase the speed and efficiency of these processes. Additionally, high-throughput screening methods enable the rapid evaluation of thousands of engineered strains or biosensors, accelerating the identification of successful designs.
Moreover, the vast amount of data generated from scaled-up experiments poses another significant challenge. As experiments become more complex and datasets grow larger, manual data analysis and interpretation are no longer feasible. The integration of computational tools, automation, and artificial intelligence (AI) in data analysis becomes crucial for managing, processing, and extracting meaningful insights from large datasets. With the ability to analyze data at scale, researchers can uncover patterns, predict outcomes, and optimize biological systems more efficiently.
Finally, scaling up synthetic biology experiments also requires new strategies for project management and collaboration. Many synthetic biology projects are interdisciplinary, involving teams of researchers with expertise in molecular biology, bioinformatics, chemical engineering, and computational modeling. Effective communication, data sharing, and coordination are essential to ensure that large-scale experiments are carried out effectively and that results can be interpreted in the context of broader scientific goals.
To meet these demands, the synthetic biology field is indulging in biofoundry development and bio-design automation. Such innovations not only make the scaling of experiments more feasible but also ensure that the results can be efficiently shared, analyzed, and utilized by researchers across the globe, regardless of their institutional resources.
We discuss the importance of linker software and the standardization of workflows by defining a High-throughput AI-based Protein Engineering (HiAPE) Stack (Figure 1), modeled after DevOps Stack. The stack refers to the suite of tools, technologies, and practices used to support the collaboration between development and operations teams throughout the software development lifecycle. It integrates various stages, including design, build, test, and learn cycles with the goal of enhancing automation, efficiency, and continuous delivery. By automating repetitive tasks and fostering close collaboration between teams, the stack enables faster, more reliable software development, improved deployment frequency, and quicker resolution of issues in production. Ultimately, it facilitates a more agile and responsive approach to software development and infrastructure management.
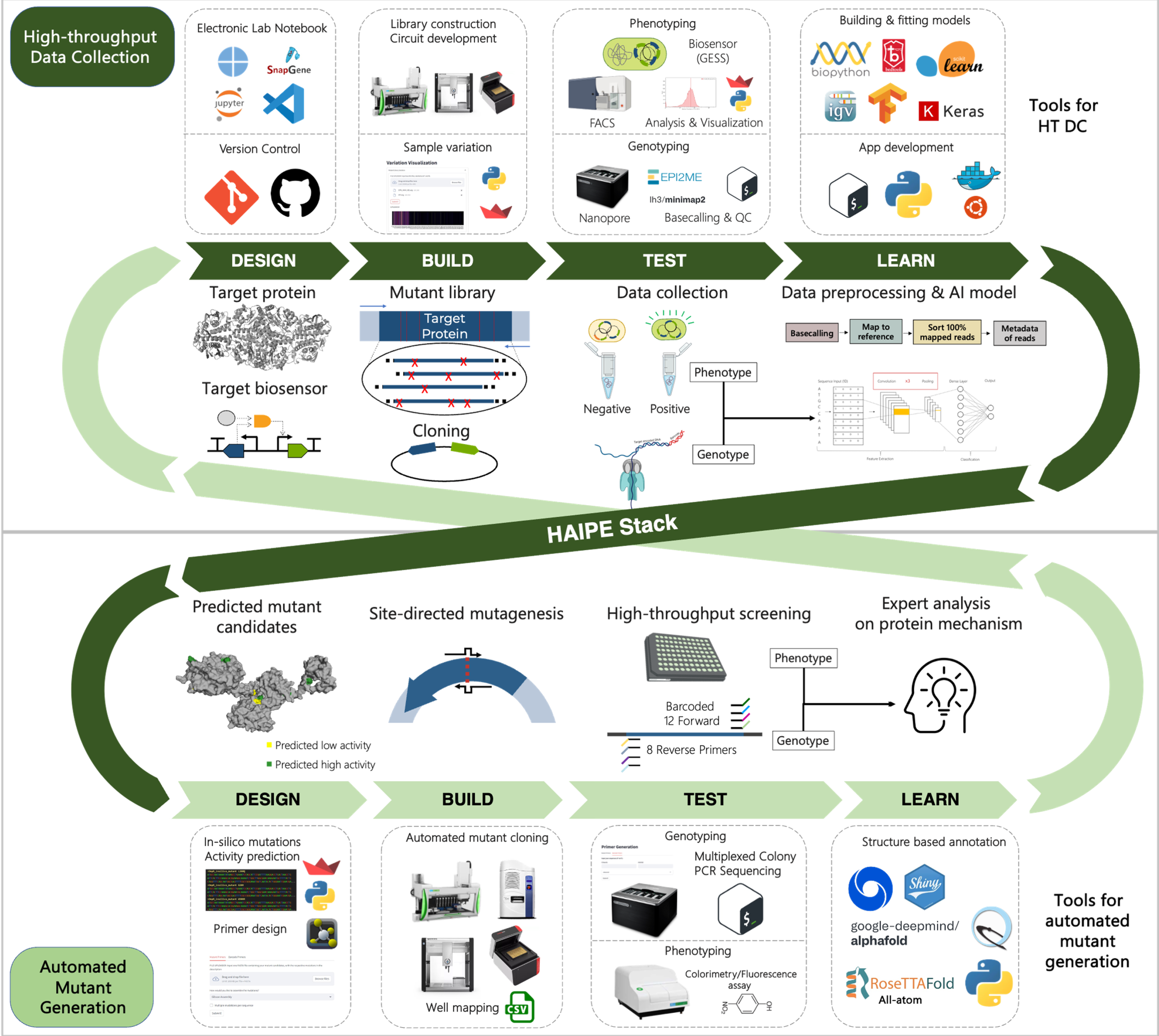
This work represents a critical starting point in the development of standard operating procedures and a scalable approaches that improve the efficiencies of both the engineering and optimizing of biological systems and the researchers that study them.